Learn how XLSTAT, a leading tool for statistical and data analysis, is now easier than ever to access through the Chest agreement. Whether you're a new user or a longtime advocate, this webinar will show how XLSTAT simplifies software procurement while enhancing research and teaching across disciplines such as Social Sciences, Biology, Business, Agriculture, and many others!
Thematic analysis offers a structured way to uncover meaningful patterns in complex data. If you’ve ever felt overwhelmed by the intricacies of this methodology – or wondered how to make it more efficient – you're not alone. For years, NVivo has been used by many researchers to do thematic analysis. Now, NVivo with Lumivero AI Assistant offers even more tools for researchers looking to put thematic analysis into practice.
To showcase just how transformative NVivo and the Lumivero platform’s AI can be for thematic analysis, Lumivero hosted a webinar featuring Dr. Ben Meehan, CEO of QDA Training, Ltd. With over two decades of experience helping others make the most of this powerful qualitative analysis software, Dr. Meehan not only emphasized NVivo’s flexibility for a wide range of research methodologies, but also demonstrated how the latest version of NVivo plus Lumivero AI Assistant can help streamline the thematic analysis process and create opportunities for richer insights from data.
Continue reading to learn more or watch the full webinar on-demand!
Dr. Meehan kicked off the webinar by addressing a common misconception about qualitative research – often seen as “touchy-feely” – and emphasized how thematic analysis, when done right, is a highly systematic and rigorous approach to making sense of complex data.
Thematic analysis has six steps, usually called “phases”. The names of these phases have evolved since Braun and Clarke’s initial paper first describing thematic analysis in 2006, “Using Thematic Analysis in Psychology.” Today, the six phases of thematic analysis are:
Dr. Meehan used the NVivo sample project, “Environmental Changes Down East,” to illustrate how the software and Lumivero AI Assistant can help researchers understand data, organize their thoughts and streamline the writing process. He created a series of folders within his project that correspond to each of the six phases and indicated that it’s best practice to copy your work over to the next folder after you complete a phase so that there’s a record of what you did with your data at each phase.
Using this multi-folder process helps researchers create an audit trail that promotes transparency. “It's there, through the production of an audit trail, that you get credibility as a researcher and, by extension, trustworthiness and plausibility to the findings,” said Dr. Meehan. He also noted that it’s possible to generate a codebook for any phase of your thematic analysis to show your supervisor, principal investigator or other stakeholders your data trail.
In the data familiarization phase, researchers immerse themselves in their data to begin understanding how it relates to their research question. In data familiarization, Dr. Meehan says, “you would be going through your interviews, and you would be writing memos and annotations and field notes, observations . . . assumptions, initial thoughts and ideas.”
He demonstrated how NVivo analysis tools can be used to help complete each of the tasks involved in data familiarization and writing familiarization notes:

Dr. Meehan pointed out two specific ways that Lumivero AI Assistant is equipped to help with this part of the process. First, summarization of transcripts, or of parts of transcripts. The AI Assistant can produce a long, standard or short summary of a transcript that offers researchers a high-level view of what topics are discussed in each interview.
“It's very useful to get your head around and start to get the data more compact and make sure you don't miss any of the really important stuff in there,” explained Dr. Meehan. “The other thing that I can do at this point is write annotations. Now, I can do an annotation with AI on a specific piece of text, or I can write it myself and that might be more useful for something like a field note or an observation.”
This helps researchers prioritize which transcripts to read in which order when they begin their close reading of each transcript – still a necessary step, Meehan explains, because “[AI] doesn't understand the language, the culture, the nuanced things. It didn't do your literature review. It doesn't know the theories that you're relating things to.”
The Lumivero platform’s AI can also be used in NVivo to summarize pieces of text within a transcript to create annotations – again, with the caveat that it’s the researcher’s responsibility to add context back where needed. Dr. Meehan also stressed that Lumivero AI Assistant is designed to protect data privacy. When you ask the AI Assistant to summarize a transcript, none of the data in that transcript is used to train the model, and no data is stored on any external servers.
Phase one is also when researchers can begin thinking about how to code their data. Dr. Meehan showed how NVivo includes a mind map functionality to help create these quickly.
Once you have completed this phase, you can copy your work to the “Phase Two” folder and begin the next step in the process.
Codes give structure to data. In reflexive thematic analysis, researchers complete three passes of coding:
NVivo offers researchers many features to help with coding.
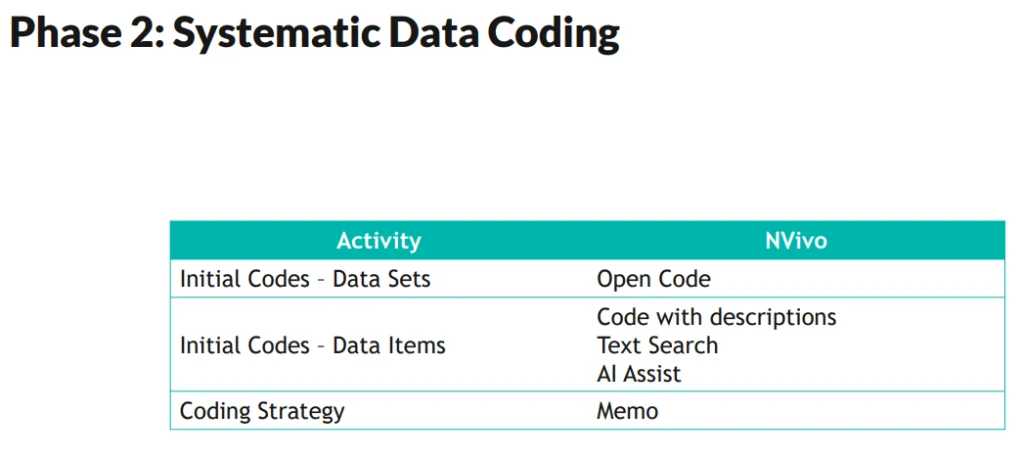
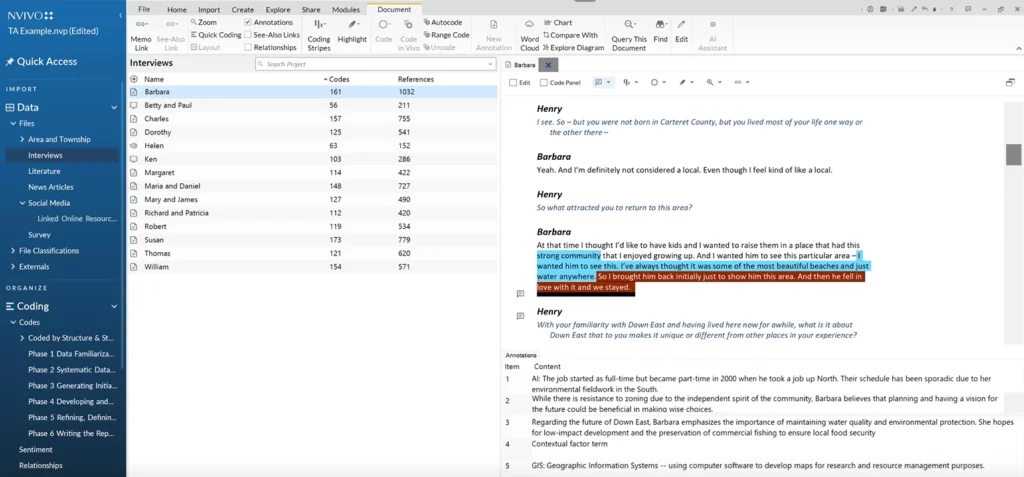
As indicated in the slide above, AI Assistant can help with suggesting initial, descriptive codes – the broad, non-hierarchical codes that give initial structure to data.
“A code behaves both like a document and a folder,” explained Dr. Meehan. “It's a document in that it can contain multiple references . . . and it's a folder in that it can contain other codes the way a folder can contain other folders. Therefore, you can put a structure on what was previously unstructured.”
Coding, Meehan concluded, is time-consuming. There’s no formula for coding that can apply to every research project. However, NVivo helps you stay organized as you code with drag-and-drop functionality, highlights, reference counts for each code you create -- among many additional features.
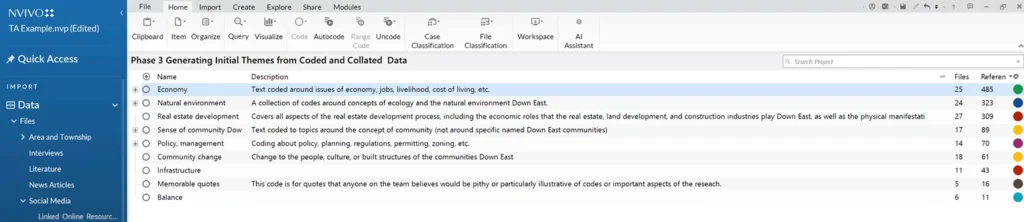
Once coding has been completed, it’s time to think about themes. Themes are groups of data that relate to the aims of your study and your research question.
“For a theme to be a theme,” Dr. Meehan said, “it has to reoccur.” Looking at codes you’ve created in NVivo with list view gives you a reference count for each code so you can identify patterns and begin to form an idea of what themes are present in your data, thanks to the reference count. Then, you can begin to sort each code area into groups. There are multiple NVivo features which can be used during this phase of thematic analysis.

Each code you create in NVivo is automatically assigned a color. (You can assign custom colors if you prefer.) You can choose to view colored coding stripes alongside your transcript, or you can generate a concept map or report to begin to understand which codes dominate in your data. Then, you can begin creating themes and sorting codes into each one.
Dr. Meehan notes that researchers should use the “description” feature to define your codes. “They’re very useful for an audit trail,” he explained, “because it means I can claim coding consistency.” Descriptions, when published with your codebook, show reviewers and other researchers your understanding of each theme.
Once initial themes are generated, it is time to move to phase four.
In phase four of thematic analysis, researchers flesh out their themes, then review them to decide which fit with the aims of the study and which should be set aside. Again, Dr. Meehan laid out which NVivo features can be used to accomplish the aims of this phase:
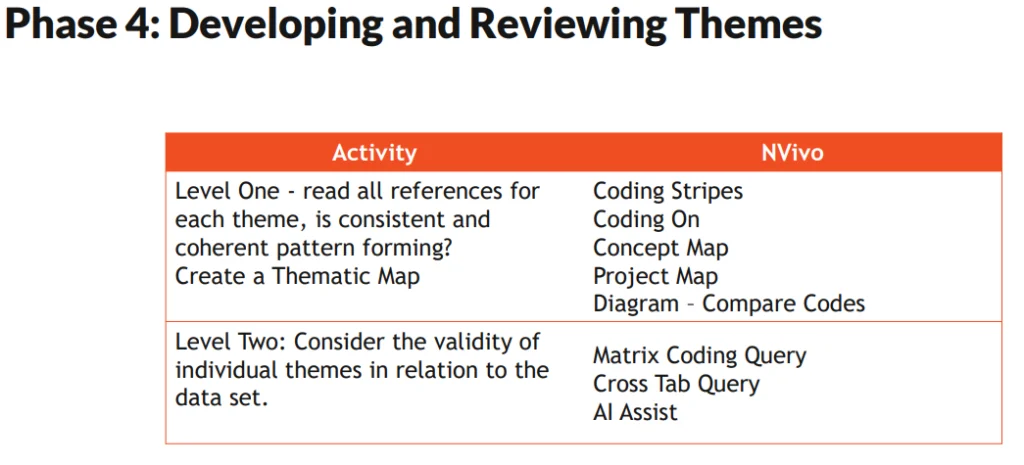
The first step is to re-evaluate all work to date. Are the references for each theme really relevant to that theme? Is a consistent pattern forming within the references? These questions should guide the process of condensing, restructuring, or even deciding to leave a theme out of the final project. Dr. Meehan notes that at a workshop he once attended with Braun and Clark, “one of the things that they [say they] encounter is that people find it difficult to let go of a theme.”
Fortunately, with the multi-folder approach Dr. Meehan describes, you don’t need to completely delete a theme – you can simply leave it in the folder for the prior phase. It will stay in your audit trail, and you will be able to access it later if you want to add it back to your current project or repurpose it for use in another one.
On the other hand, there may be some broad themes that need to be fleshed out. This process is called “coding-on” where you look at all the references coded to a broad theme and then code them into finer themes. Dr. Meehan notes that Lumivero AI Assistant can be of great use at this stage. Selecting a theme and then using the “suggest child codes” option under the AI Assistant function will prompt AI Assistant to quickly review all the references tagged under that theme. It will then generate a potential list of sub-codes that you can review and approve.
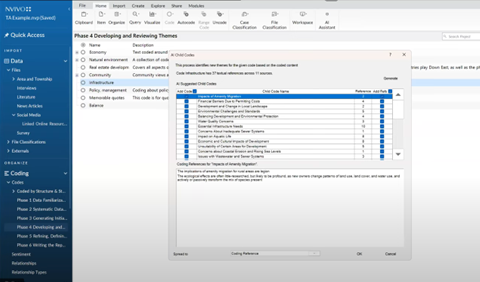
Any code suggestion you approve will automatically pull the references through, saving you significant time during this step. Dr. Meehan stressed that this feature should only be used for additional descriptive codes. “[AI] wouldn't do the interpretive stuff,” he explained. “Just be careful you don't fall into that trap. It still requires humans to do that.”
Once the themes are developed and reviewed, it’s time to read through each code and consider the data more deeply. Researchers should be “looking at the different arguments, the different experiences, attitudes, beliefs or behaviors that people are talking about in the interviews,” said Dr. Meehan.
With phase five, “we’re moving toward endgame,” said Dr. Meehan. This phase of thematic analysis uses fewer tools in NVivo, however, the manual analysis work that needs to be done is considerable. Additional memoing, along with cross-referencing and linking, allows researchers to further condense their themes to what is most essential in terms of the research question.

Work through each theme, writing an analysis that pulls in details which connect to the research question. The goal of this phase is to develop a thematic framework for writing your final product. Once that is done, you can begin to write.
NVivo with AI offers qualitative researchers a wide range of tools for streamlining the writing process:
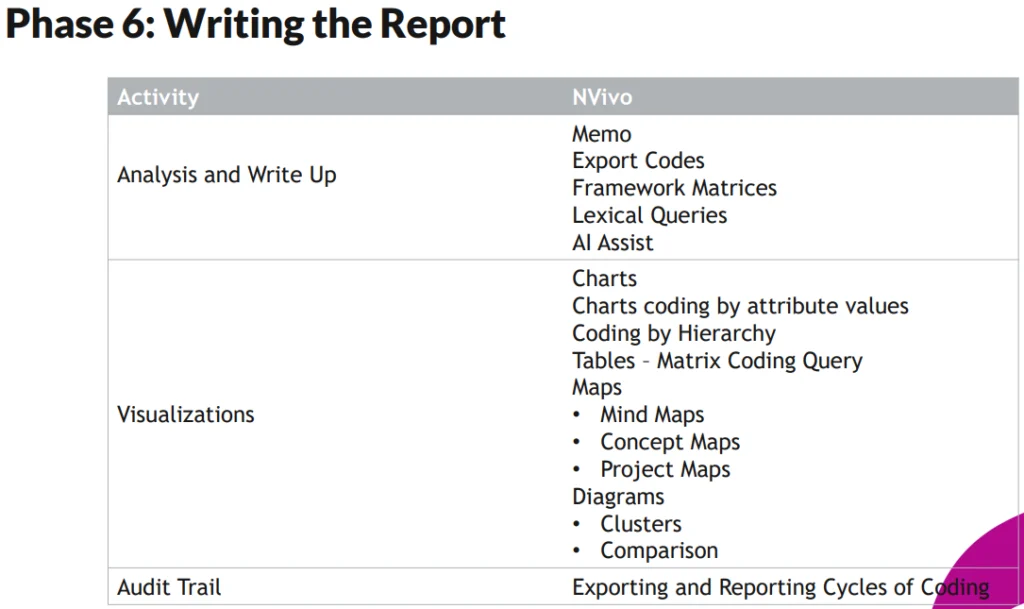
Dr. Meehan encouraged attendees to seek out a 2009 paper by Australian academic Pat Bazeley, “Analyzing Qualitative Data: More Than Identifying Themes” to understand how to approach the writing phase. “Too often,” says Bazeley, “qualitative researchers rely on the presentation of key themes supported by quotes from participants’ text as the primary form of analysis and reporting of their data.”
Bazeley advises researchers to work from the data to develop a more robust analysis. In her paper, she uses an earlier version of NVivo to demonstrate what’s possible.
Back in the webinar, Dr. Meehan recommended adding a number to each theme and subtheme to match the order in which you intend to present them in your final work. This can be changed as you continue analyzing your data and your themes.
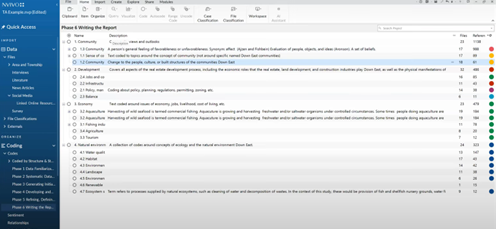
Then, begin working through each section, writing a detailed memo that describes key findings. It’s possible to use AI Assistant to help you jump-start this process, but Dr. Meehan reiterated that AI Assistant can only provide a surface-level summary. It’s up to you to interpret the data and provide context.
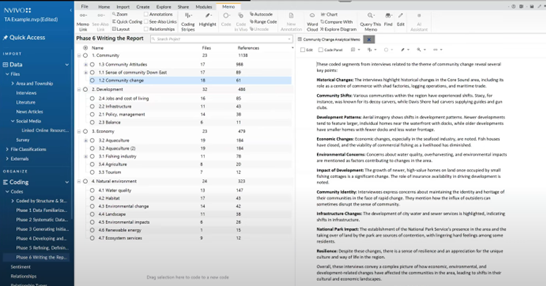
As you write your memo, you will be able to link each code back to its original references or pull illustrative quotes through from transcripts. This supports your audit trail and also allows you to quickly revisit references to re-evaluate your original data.
During this phase, you can also conduct a sentiment analysis or quickly generate visualizations for each theme to understand the relationships between codes. Dr. Meehan showed several examples of the visualizations you can create with NVivo to enable deeper analysis of qualitative data. One was this hierarchical chart, which showed which codes dominated a theme:
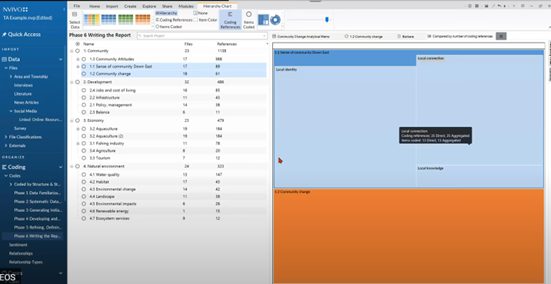
It’s also possible, depending on how you’ve coded, to generate visualizations by attribute value, such as the age groups of speakers, to see whether a specific demographic is more concerned with the theme than others.
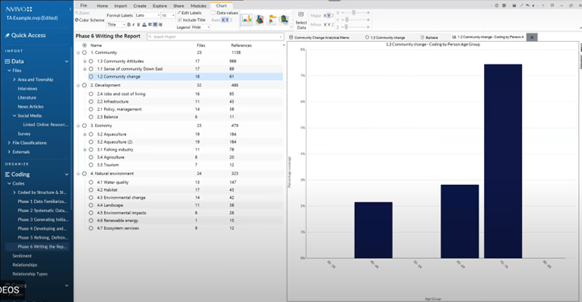
Any visualizations you create can be copied and pasted into your memos. “It's not much technical input required,” explained Meehan. “It's drag and drop and . . . they'll all export as high-resolution images in multiple formats.”
Finally, he showed how NVivo with AI could quickly generate matrices by dragging and dropping different attributes to compare. Framework matrices and crosstabs are just two examples of how you can further visualize your qualitative data with NVivo. Export your files to Word, and you’re good to begin your final writing.
Need a better research writing and knowledge management tool? Discover Citavi!
Dr. Meehan’s webinar highlighted the power of NVivo and Lumivero AI Assistant in streamlining thematic analysis and uncovering deeper insights. Whether you’re new to NVivo or looking to upgrade your software for qualitative analysis, now is the perfect time to explore its capabilities. Watch the full webinar for a comprehensive walkthrough, or request a demo to see how NVivo can revolutionize your research process.
Delve into the ethical dimensions of conducting qualitative research in the age of AI with Dr. Susanne Friese, while acknowledging that ethical considerations have always been paramount, even before AI's advent.
In this webinar, we will explore the nuanced challenges introduced by AI technologies such as data privacy, consent, and the potential for bias and hallucinations, and offer recommendations on how to address these challenges. Additionally, Dr. Susanne Friese will introduce a method for ethically using generative AI to analyze qualitative data, including discussions on the often-overlooked limitations of LLMs. The session will also cover how to incorporate AI findings into reports, theses, or journal articles.
Whether you're a seasoned researcher or new to the field, this webinar will provide valuable insights on balancing innovation with ethical considerations, ensuring that your research practices are both cutting-edge and conscientious. Join us to learn how to ethically integrate AI into your qualitative research and scientific writing.
As budget season approaches, BioPharma companies prepare for portfolio selection. Traditional prioritization techniques often lead to value destruction. Effective portfolio selection requires considering multiple strategic alternatives and multi-year constraints. This webinar highlights the importance of evaluating trade-offs between financial objectives (e.g., sales, cash flow) to simplify complex decisions.
Using Evolver and RISKOptimizer of the DecisionTools Suite, Dr. Bayney will show how to optimize portfolio selection by finding the best combination of project alternatives within annual and multi-year budget constraints.
While this session focuses on single-objective optimization, a future session will explore the MiniMax Q technique for multiple-objective portfolio optimization.
At the core of any simulation model is a set of probabilities. Are they the right probabilities? Are they actually representative of the uncertainties you are facing? And how do you know?
In this talk, Tim Nieman will discuss some of the pitfalls in assessing probabilities, especially the ever-present cognitive biases, and how to minimize (but not eliminate!) these issues. The webinar will include some fun polls to test and potentially illuminate your own biases.
The 2024 Lumivero Virtual Conference on Sept. 25-26 brought together a diverse global community of data professionals, researchers, academics, and students for sessions featuring data intelligence, research trends, data analysis, risk management, and student success. With more than 6,200 registrations from 161 countries, the event highlighted Lumivero's ever-growing impact across industries such as education, social sciences, and public health.
Conference Highlights:
Missed it? You can still catch the sessions on demand! In this article, we’ll highlight some of the key sessions and impactful themes from the event to help you get started.
The conference focused on key themes addressing the evolving needs of researchers, data analysts, and professionals. Sessions covered practical strategies, the role of artificial intelligence (AI), innovative approaches to research and data management, and more.
These themes not only addressed the pressing needs of today’s professionals, but also provided valuable tools and strategies to help attendees stay ahead in their respective fields.
The 2024 Lumivero Virtual Conference featured dynamic keynote sessions led by thought leaders at the forefront of research and data analysis. These sessions offered deep insights into the latest trends, challenges, and opportunities in the industry, making them must-watch experiences for all!
Missed it live? All sessions are available on demand! Expand your skills, stay ahead of trends, and explore new strategies to make data-driven decisions.
Discover the latest version of XLSTAT, specifically designed to elevate data visualization, market research, and consumer insights. Join this interactive webinar to explore how these powerful tools can transform your business or research—and see them in action through a live demonstration!
There are many different types of waste in manufacturing – waste that can cost the economy many billions of dollars per year. For example, a 2022 McKinsey report on food loss (food wasted during harvest and processing) estimated a global cost of $600 billion per year for growers and manufacturers. Unplanned downtime due to breakdowns of production equipment is another type of waste, and a 2023 analysis of the cost of downtime by Siemens (p. 2) estimates that this wasted time costs Fortune Global 500 companies 11% of their annual turnover.
Management experts have tried to solve the problem of waste in manufacturing for generations. Today, many organizations have adopted Lean Six Sigma, a popular managerial methodology that helps improve processes, reduce waste, and ensure the quality of products.
In this article, you'll gain clear definitions of Lean and Six Sigma, a deeper understanding of the principles of Lean Six Sigma, and details on the Lean Six Sigma certifications available to practitioners.
First, let’s define Lean Six Sigma. As mentioned above, Lean Six Sigma is a management methodology that aims to streamline operations, boost efficiency, and drive continuous improvement. While it has its roots in manufacturing, Lean Six Sigma has also been adopted by other industry sectors including finance and technology.
Lean Six Sigma originates from two separate methodologies, Lean and Six Sigma. Both these methodologies have their own rich histories.
Lean principles have their roots in the automotive manufacturing sector. According to an article by the Lean Enterprise Institute, Lean principles emerged from the Toyota Production System (TPS), which was developed in Japan after WWII.
Taiichi Ohno, a production expert and Executive Vice President at Toyota, is considered the father of TPS. According to his entry in the Encyclopedia Britannica, Ohno developed a production system he called “just-in-time” manufacturing. The Toyota Europe website describes the just-in-time approach as “making only what is needed, when it is needed, and in the quantity needed, at every stage of production.”
When the TPS began to be studied and implemented in the United States, it evolved into Lean manufacturing. “Lean” was coined by then-MIT researcher John Krafcik, and defined in the 1996 book Lean Thinking by the researchers James Womack and Daniel Jones. In the introduction to their book, Womack and Jones describe Lean as a methodology which “provides a way to specify value, line up value-creating actions in the best sequence, conduct these activities without interruption whenever someone requests them, and perform them more and more effectively.” (p. 6) Lean principles have since moved beyond industrial production to construction, technology, and other industries.
According to an article by Six Sigma education provider Six Sigma Online, Six Sigma is a data-driven method developed by engineers at Motorola in the 1980s to reduce defects in manufacturing processes. The term “Six Sigma” refers to a process that produces “no more than 3.4 defects per million opportunities, which equates to six standard deviations (sigma) between the process mean and the nearest specification limit.”
Six Sigma spread to other businesses, achieving mainstream popularity when Jack Welch, then-CEO of General Electric, embraced it as a key part of GE's business strategy in the 1990s. In 2011, it was formally standardized by the International Standards Organization.
In the early 2000s, organizations realized that combining Lean’s focus on waste reduction with Six Sigma’s focus on process improvement through data-driven techniques could create a powerful, complementary approach to process optimization. Lean Six Sigma was born as a hybrid methodology focused on both eliminating waste (Lean) and reducing defects and variation (Six Sigma). Or, as Momal put it in his webinar on Monte Carlo Simulation, “when we're talking Six Sigma, we mainly talk about quality, and when we're talking lean, we mainly talk about speed.”
The methodology of Lean Six Sigma revolves around key principles drawn from both foundations. These principles guide how businesses can identify problems, find solutions, and sustain improvements. In an extract from the book Lean Six Sigma for Leaders published on the Chartered Quality Institute’s website, authors Martin Brenig-Jones and Jo Dowdall list these principles:
Focus on the Customer
Lean Six Sigma begins with ensuring that the organization understands the customer’s needs and expectations, then aligns processes to meet those requirements. This means eliminating activities that do not directly contribute to customer satisfaction.
Identify and Understand the Process
Before improving any process, it's essential to understand how it works. Lean Six Sigma uses tools like process mapping to visualize workflows and identify bottlenecks or unnecessary steps. The aim is to achieve a smooth, consistent process that maximizes efficiency.
“Manage by Fact” to Reduce Variation and Defects
Six Sigma emphasizes reducing variation within processes, ensuring that outcomes are consistent and predictable. This principle is based on data analysis and statistical tools that help identify the root causes of defects or inefficiencies. By reducing variation, companies can deliver products or services that meet quality standards with minimal defects.
Eliminate Waste
Lean principles focus on identifying and eliminating different types of waste within a process. Waste can be anything that doesn’t add value to the final product, such as excess inventory, waiting time, unnecessary movement, or overproduction. The goal is to streamline processes, minimize resource usage, and increase value-added activities.
There are seven types of waste Lean aims to eliminate. These were originally identified during the development of the TPS. Toyota describes them in a 2013 article about the TPS as:
Empower Teams and Foster Collaboration
Lean Six Sigma emphasizes teamwork and empowering employees to contribute to process improvements. Employees are trained in Lean Six Sigma tools, creating a culture of continuous improvement.
Continuous Improvement (Kaizen)
Both Lean and Six Sigma emphasize kaizen, a Japanese term meaning “continuous improvement.” The Kaizen Institute explains that this principle also originated from the TPS. Kaizen involves regularly assessing processes to make incremental improvements.
Data-Driven Decision Making
One of the core elements of Six Sigma is its reliance on data to make decisions. Lean Six Sigma practitioners use data to understand the current state of processes, measure performance, and determine whether improvements have been successful.
Practitioners can pursue certifications in Lean Six Sigma to demonstrate their ability to apply the principles to projects and processes. These certifications are described as “belts,” and follow a color system similar to that found in many East Asian martial arts. An article from the consultancy Process Management International lists the belt certifications from newest practitioner to most experienced starting with the white belt to the final master Six Sigma black belt:
Now that you’ve explored the fundamentals of Lean Six Sigma, you’re ready to discover how powerful risk analysis tools like @RISK can further enhance project outcomes.
Check out the next article, Using @RISK to Support Lean Six Sigma for Project Success, where we’ll showcase real-world examples from François Momal’s webinar series, demonstrating how organizations apply Monte Carlo simulation in @RISK to successfully implement Lean Six Sigma.
Ready to get started now? Request a demo of @RISK.
In our previous article, Introduction to Lean Six Sigma, we discussed the fundamentals of Lean Six Sigma, exploring how it combines the principles of lean manufacturing and Six Sigma to drive process improvement and operational excellence.
Now, we’re taking the next step by diving into how risk analysis software, specifically with Lumivero’s @RISK software, can enhance Lean Six Sigma initiatives. This post will focus on how Monte Carlo simulation can empower organizations to predict, manage, and mitigate risks, ensuring the success of Lean Six Sigma projects by drawing from insights shared in François Momal’s webinar series, “Monte Carlo Simulation: A Powerful Tool for Lean Six Sigma” and “Stochastic Optimization for Six Sigma.”
Together, we’ll explore real-world examples of how simulation can optimize production rates, reduce waste, and foster data-driven decision-making for sustainable improvements.
Monte Carlo simulation, as a reminder, is a statistical modeling method that involves making thousands of simulations of a process using random variables to determine the most probable outcomes.
The first model Momal presented involved predicting the lead time for a manufacturing process. He described the question this model could answer as, “when I give a fixed value for my process performance to an internal or external customer, what is the associated risk I take?”
Using data on lead time for each step of a six-step production process, @RISK ran thousands of simulations to determine a probable range for the lead time. It produced three outputs:\
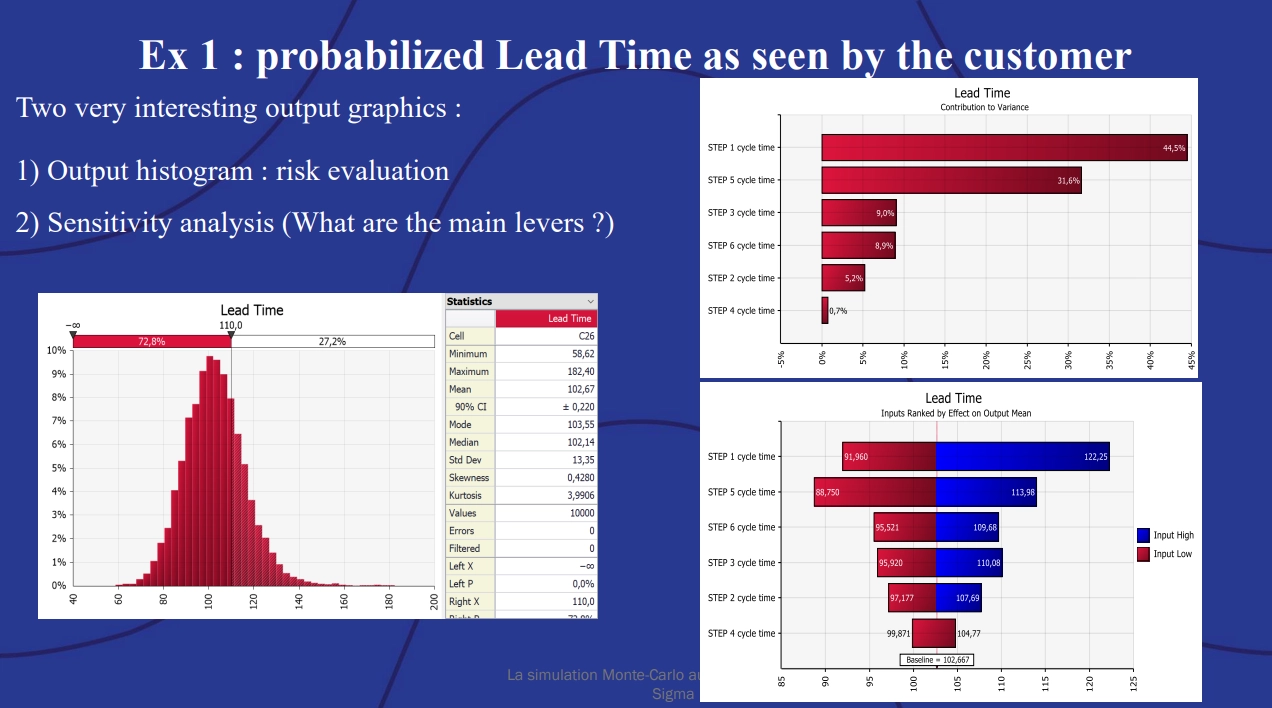
Example 1: Probable lead time as seen by the customer showing two output graphics: output histogram for risk evaluation and sensitivity analysis showing what the main levers are.
The left-hand chart shows the probability distribution curve for the lead time which allows the production manager to give their customer an estimate for lead time based on probability. The other two charts help identify which steps to prioritize for improvement. The upper right-hand chart shows which of the six steps contribute most to variation in time, while the lower-right hand chart describes how changes to the different steps could improve that time.
@RISK also allows production managers to set probability-based improvement targets for each step of the process using the Goal Seek function.
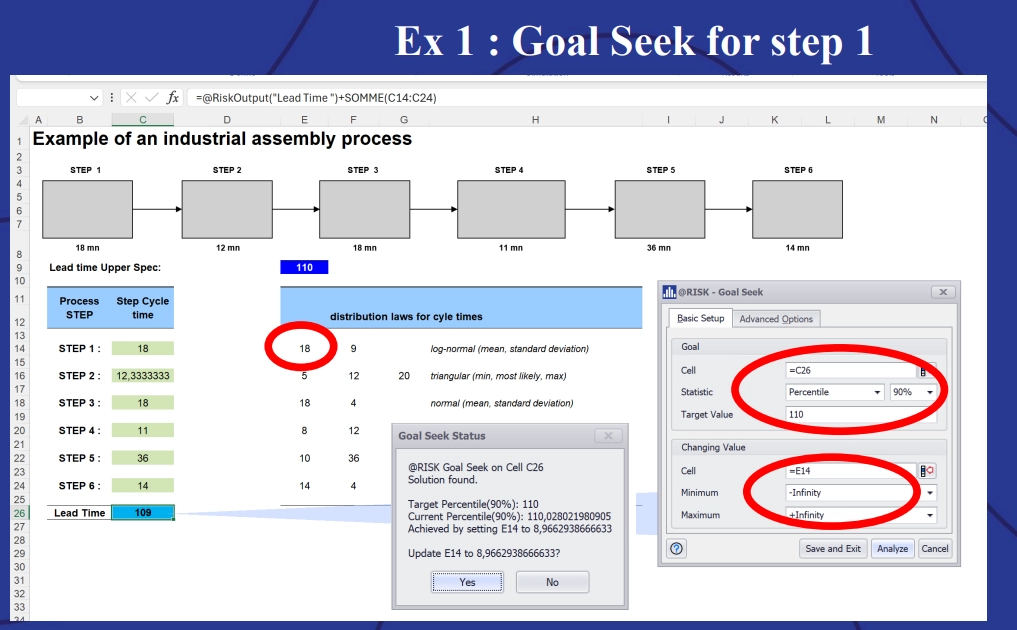
Example 1: Goal Seek for step 1. Example of an industrial assembly process.
As mentioned above, the “Lean” aspect of Lean Six Sigma often refers to speed or efficiency of production. Lean production relies on being able to accurately measure and predict the hourly production rates of an assembly line.
Momal’s second example was a model which compared two methods of finding estimated production rates for a five-step manufacturing process: a box plot containing 30 time measurements for each step, and a Monte Carlo simulation based on the same data.
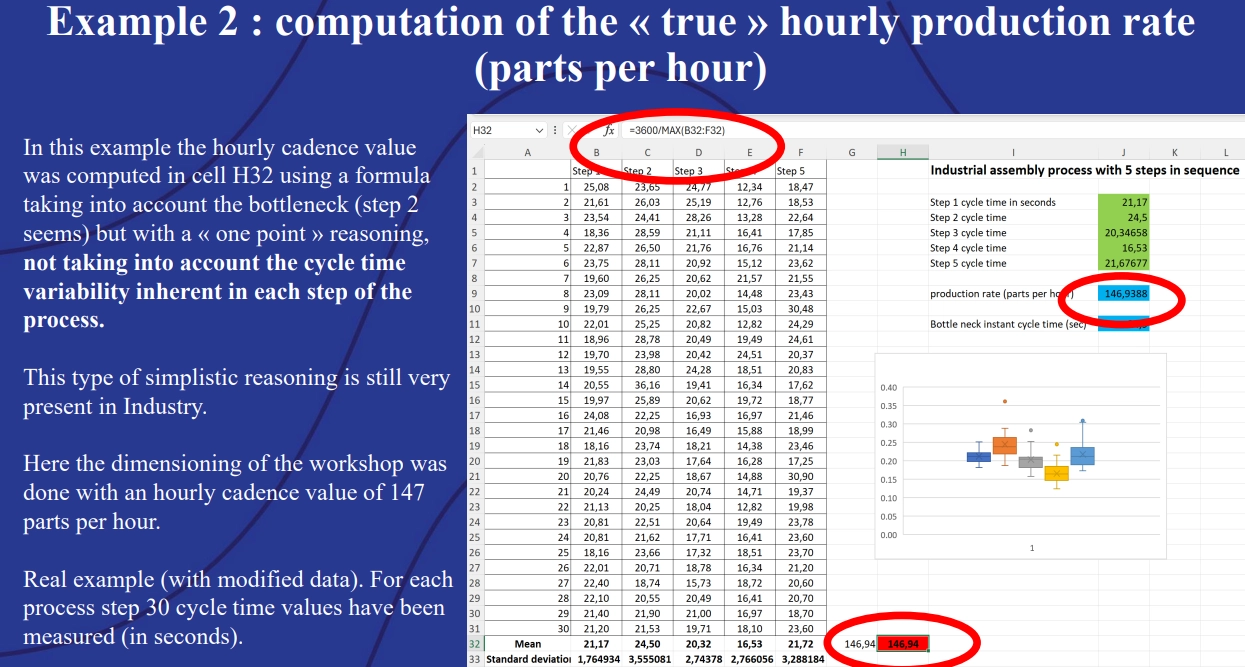
Example 2: Computation of the true hourly production rate (parts per hour).
Both the box plot and the Monte Carlo simulation accounted for the fact that step two of the production process was often slower than the others – a bottleneck. However, the box plot only calculated the mean value of the time measurements, arriving at a production rate of approximately 147 units per hour. This calculation did not account for variability within the process.
Using @RISK to apply Monte Carlo simulation to the model accounts for this variance. The resulting histogram shows that the assembly line only achieves a production rate of 147 units per hour in 37.2% of simulations.
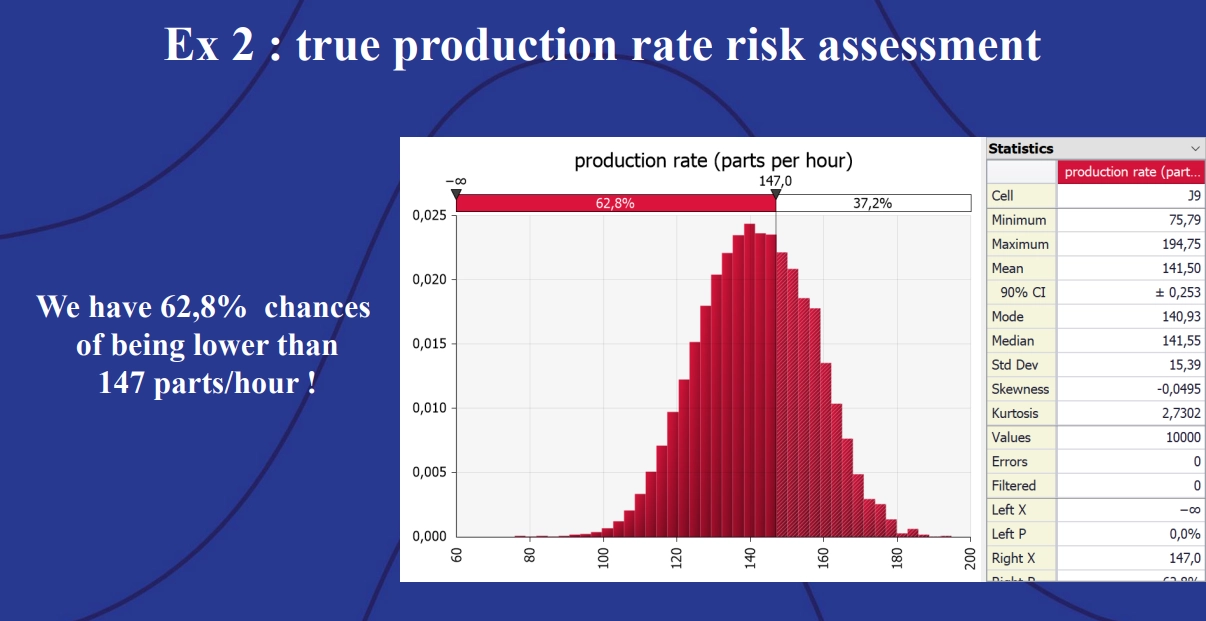
Example 2: True production rate risk assessment.
A plant manager trying to achieve 147 units per hour will be very frustrated, given that there is a 62.8% chance the assembly line will not be able to meet that target. A better estimate for the engineers to give the plant manager would be 121.5 units per hour – the production line drops below this rate in only 10% of simulations:
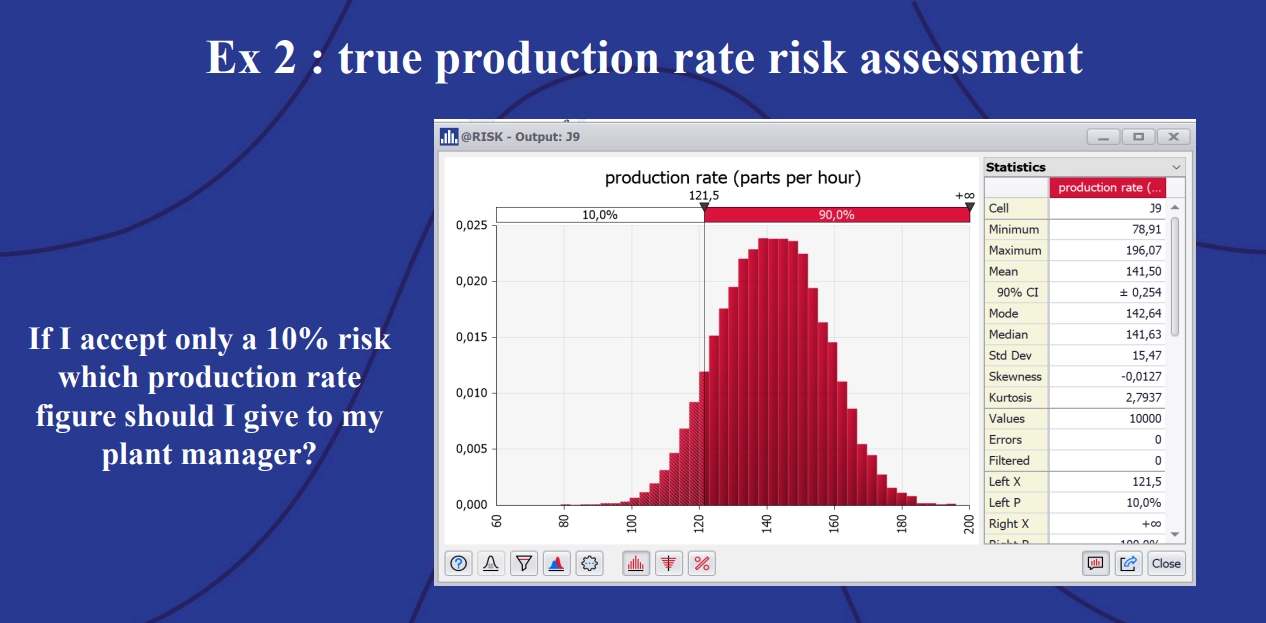
Example 2: True production rate risk assessment, accepting a 10% risk.
Furthermore, with the Monte Carlo simulation, engineers working to optimize the assembly line have a better idea of exactly how much of a bottleneck step two of the process causes, and what performance targets to aim for to reduce its impact on the rest of the process. “The whole point with a Monte Carlo simulation,” explained Momal, “is the robustness of the figure you are going to give.”
From Lean modeling, Momal moved on to Six Sigma. Monte Carlo simulation can be applied to tolerancing problems – understanding how far a component or process can deviate from its standard measurements and still result in a finished product that meets quality standards while generating a minimum of scrap.
Momal used the example of a piston and cylinder assembly. The piston has five components and the cylinder has two. Based on past manufacturing data, which component is most likely to fall outside standard measurements to the point where the entire assembly has to be scrapped? A Monte Carlo simulation and sensitivity analysis completed with @RISK can help answer this question.

Example 3: Tolerancing of an assembled product, showing a cost-based stack tolerance analysis chart.
In this tolerance analysis, the assembly gap (cell C6) must have a positive value for the product to fall within the acceptable quality range. Using a fixed quality specification, it’s possible to run a Monte Carlo simulation that gives the probability of production meeting the specified assembly gap given certain variables.
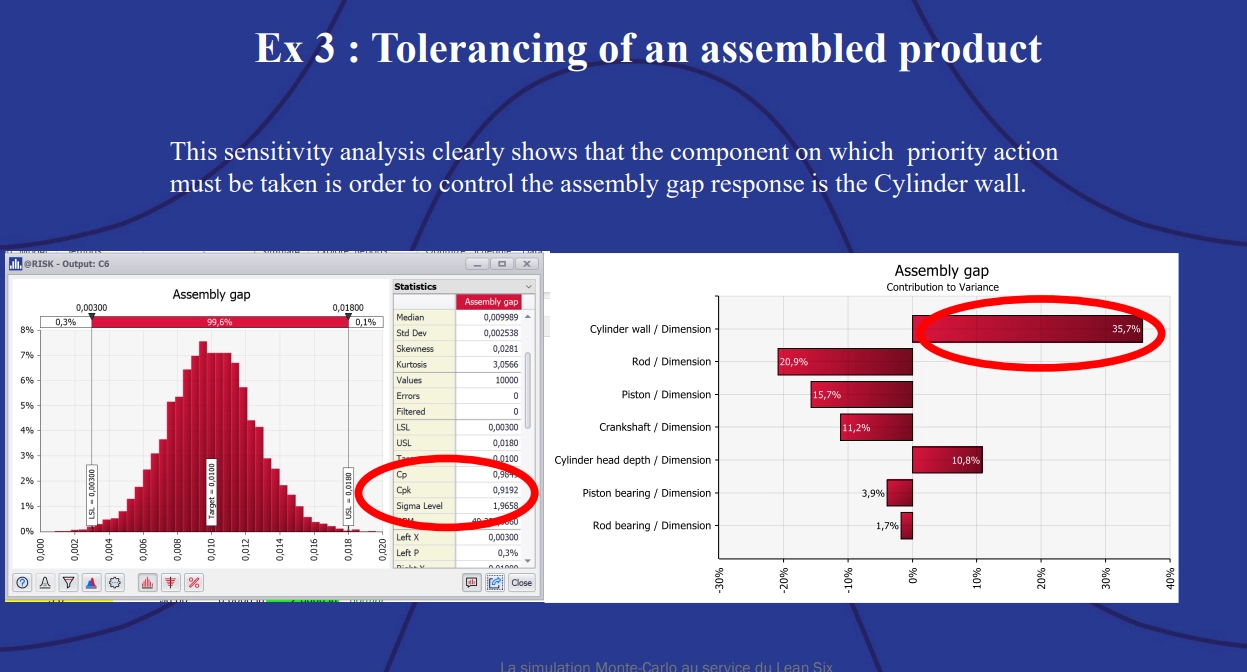
Example 3: Tolerancing of an assembled product, showing sensitivity analysis.
Then, using the sensitivity analysis, engineers can gauge which component contributes the most variation to the assembly gap. The tornado graph on the right clearly shows the cylinder wall is the culprit and should be the focus for improving the quality of this product.
Stochastic optimization refers to a range of statistical tools that can be used to model situations which involve probable input data rather than fixed input data. Momal gave the example of the traveling salesman problem: suppose you must plan a route for a salesman through five cities. You need the route to be the minimum possible distance that passes through each city only once.
If you know the fixed values of the distances between the various cities, you don’t need to use stochastic optimization. If you’re not certain of the distances between cities, however, and you just have probable ranges for those distances (e.g., due to road traffic, etc.), you’ll need to use a stochastic optimization method since the input values for the variables you need to make your decision aren’t fixed.

Stochastic optimization: A double nested loop with decision variables (also named optimization variables).
Within the stochastic optimization simulation, a Monte Carlo simulation is completed for each variable within the “inner loop,” and then another Monte Carlo simulation is run across all the variables using different values (the “outer loop”).
For Lean Six Sigma organizations, stochastic optimization can support better project planning. Momal’s first model showed how to run a stochastic optimization to determine which project completion order would maximize the economic value add (EVA) of projects while minimizing time and labor costs so they remain within budget.

Example 4 Choice of Six Sigma projects to be launched in priority.
To use @RISK Optimizer, users must define their decision variables. In this model, Momal decided on simple binary decision variables. A “1” means the project is completed; a “0” means it isn’t. Users must also define any constraints. Solutions found by the simulation which don’t fit within both constraints are rejected.
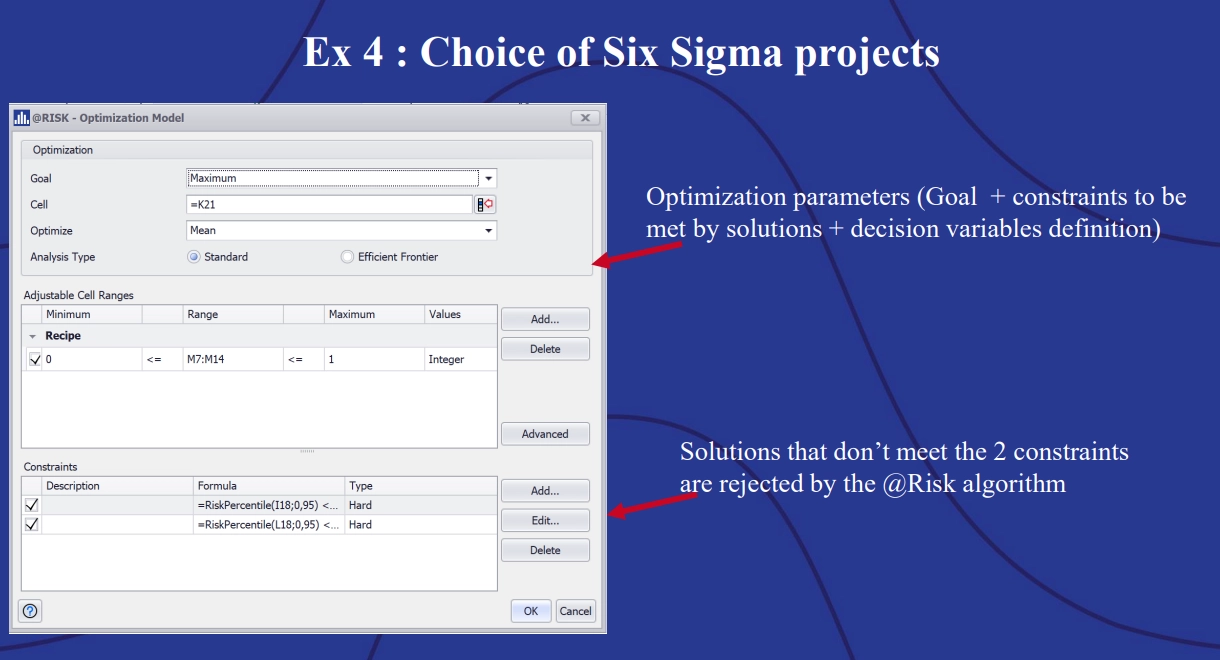
Example 3: Choice of Six Sigma projects, showing optimization parameters and solutions that don’t meet the two constraints.
The optimization was run with the goal of maximizing the EVA. With @RISK, it’s possible to watch the optimization running trials in real time in the progress screen. Once users see the optimization reaching a long plateau, it’s generally a good time to stop the simulation.
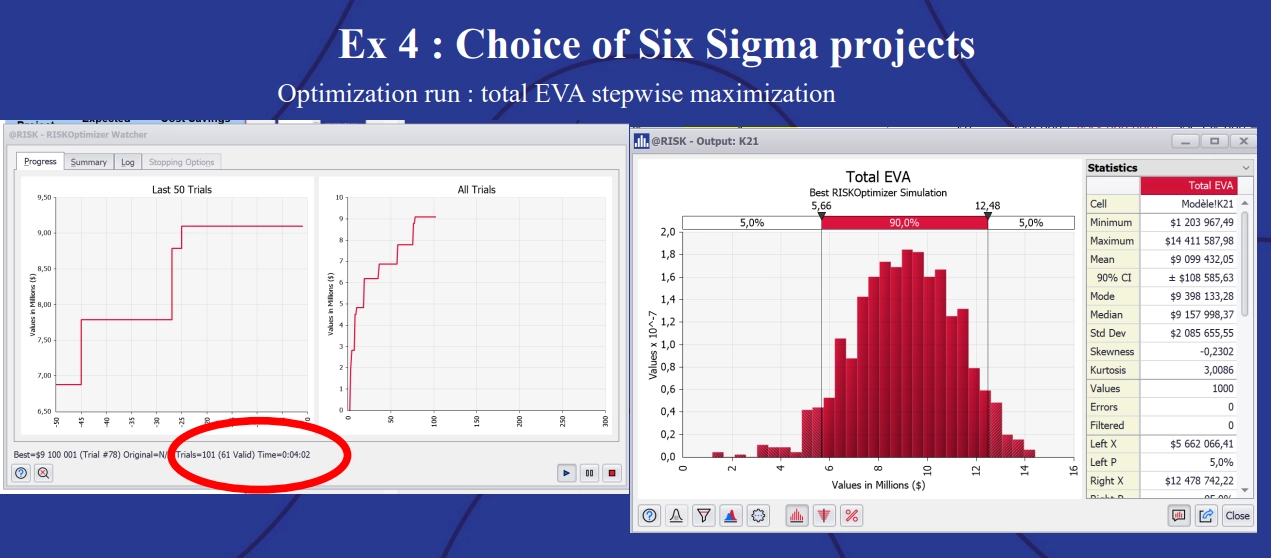
Example 4: Choice of Six Sigma projects showing optimization run: total EVA stepwise maximization.
In this instance, the stochastic optimization ran 101 trials and found that only 61 were valid (that is, met both of the constraints). The best trial came out at a maximum EVA of approximately $9,100,000. The projects selection spreadsheet showed the winning combination of projects:
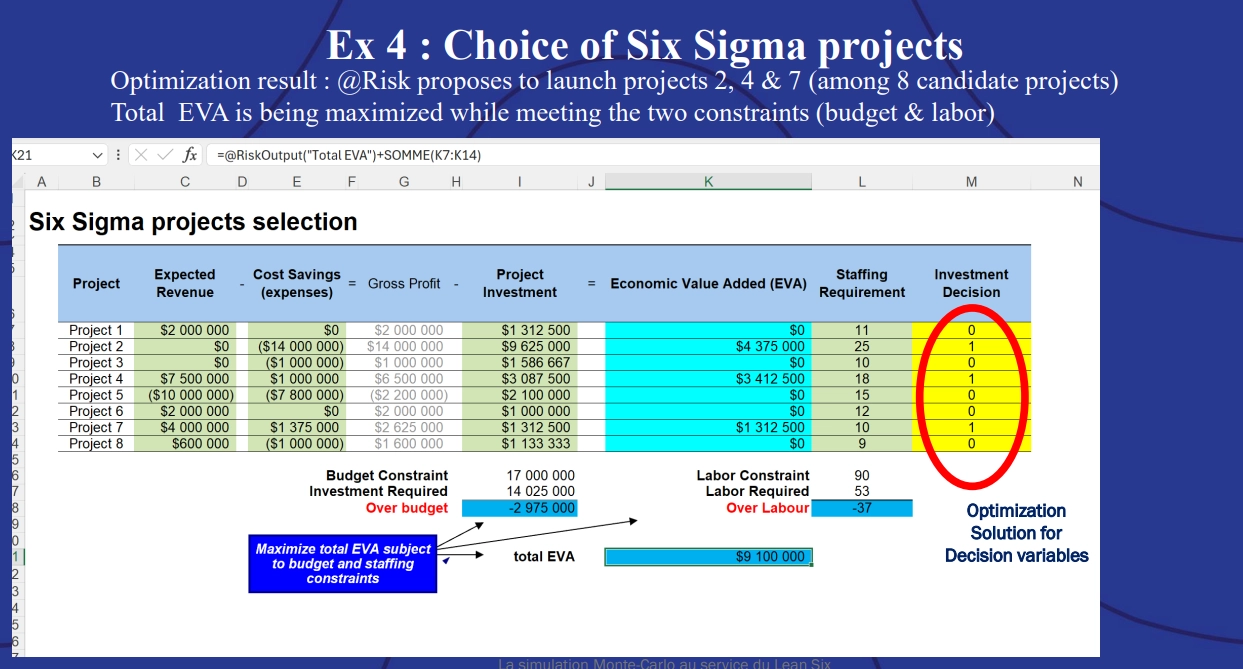
Example 4: Choice of Six Sigma projects optimization results.
Of the eight candidate projects involved, @RISK says that projects 2, 4, and 7 will meet the budget cost and labor time constraints while maximizing the EVA.
Next, Momal showed how stochastic optimization can be applied to design problems – specifically within the Design for Six Sigma (DFSS) methodology. DFSS is an approach to product or process design within Lean Six Sigma. According to a 2024 Villanova University article, the goal of DFSS is to “streamline processes and produce the best products or services with the least amount of defects.”
DFSS follows a set of best practices for designing components to specific standards. These best practices have their own terminology which Six Sigma practitioners must learn, but Momal’s model can be understood without them.
The goal of this demonstration was to design a pump that minimizes manufacturing defects and cost per unit.
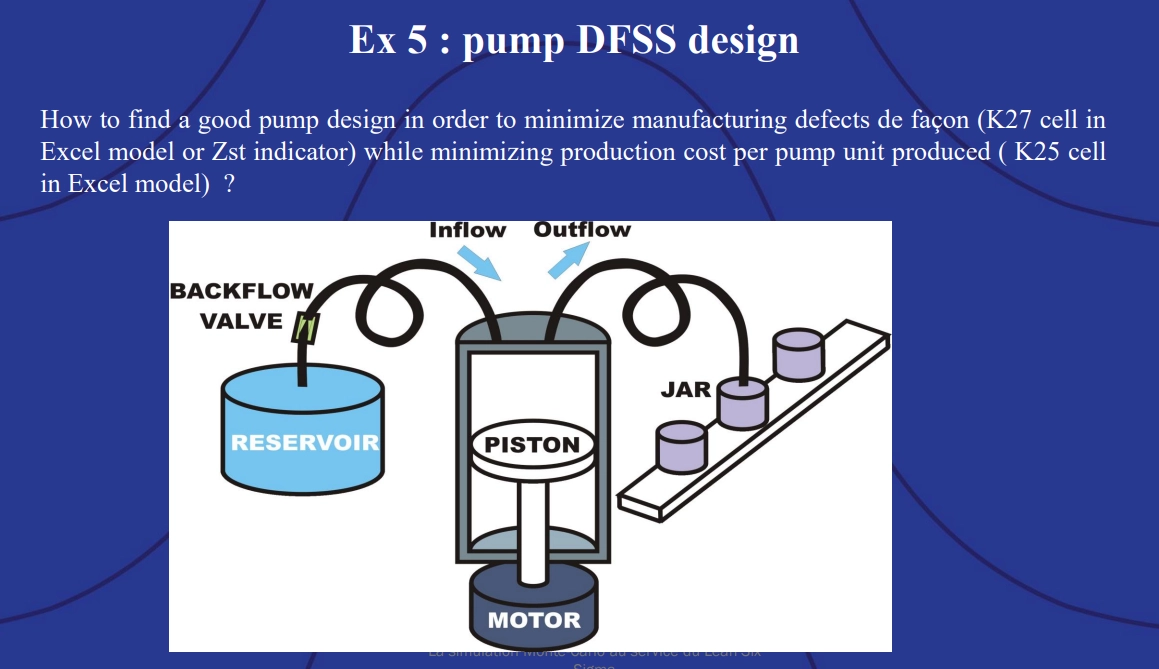
Example 5: Pump DFSS design.
The model used to set up the stochastic optimization included a set of quality tolerances for the flow rate of the pump – this is what is known in DFSS as the “critical to quality” (CTQ) value – the variable that is most important to the customer. Decision variables included motor and backflow component costs from different suppliers as well as the piston radius and stroke rate. The goal was to minimize the unit cost and the quality level of the pump while meeting the flow rate tolerances.

Example 5: Pump DFSS design showing decision variables and tolerances.
As with the previous model, Monal demonstrated how to define the variables and constraints for this model in @RISK.

Example 5: Pump DFSS design, answering the question of “how can we guarantee a certain level of quality?”.
Then, when Monal ran the simulation, he again watched the live progress screen within @RISK to see when a plateau was reached in the results. He stopped the simulation after 1,000 trials.
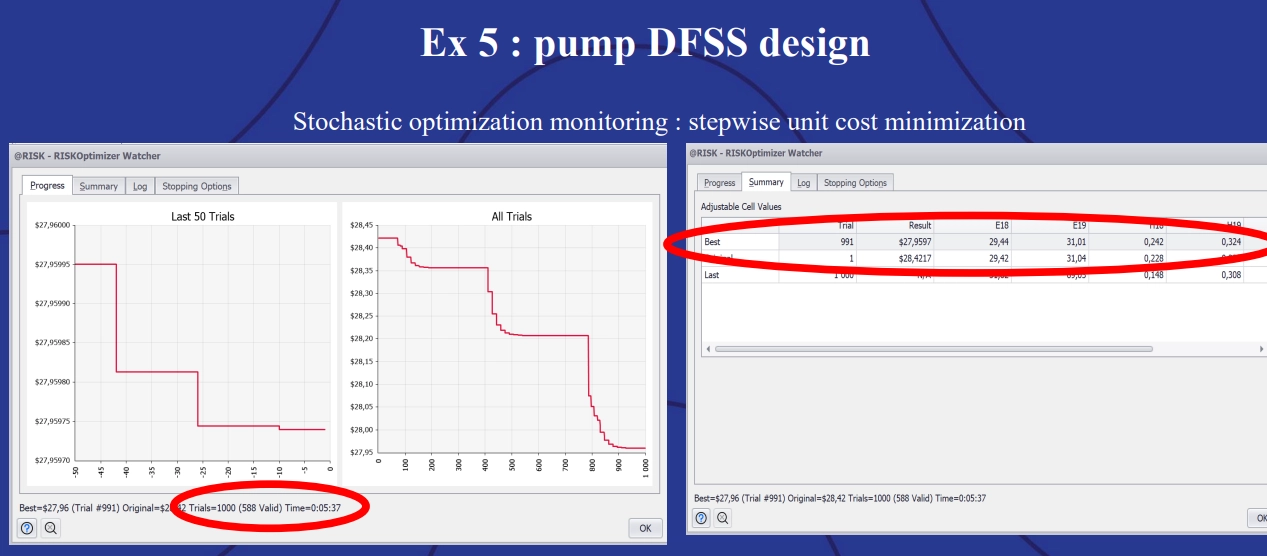
Example 5: Pump DFSS design, showing stochastic optimization monitoring.
The simulation showed that trial #991 had the best result, combining the lowest cost while meeting the CTQ tolerances. Finally, @RISK updated the initial stochastic optimization screen to show the best options for supplier components.
Experiments are necessary in manufacturing, but they are expensive. Six Sigma methodology includes best practices for design of experiments (DOE) that aims at minimizing the cost of experiments while maximizing the amount of information that can be gleaned from them. Monal’s final model used XLSTAT to help design experiments which would solve an issue with a mold injection process that was causing too many defects – the length of the part created should have been 63 mm.
The approach involved running a DOE calculation in XLSTAT followed by a stochastic optimization in @RISK. There were three known variables in the injection molding process: the temperature of the mold, the number of seconds the injection molding took (cycle time), and the holding pressure. He also identified two levels for each variable: an upper level and a lower level.

Example 6: Monte Carlo simulation – DOE coupling.
Six Sigma DOE best practices determine the number of prototype-runs an experiment should attempt by taking the number of levels for the variables, then raising them to the power of the overall number of variables, and finally multiplying that value by five. In this instance, 23 is equal to 8, and 8 x 5 is 40. There should be 40 real prototypes generated. These were modeled with XLSTAT DOE. The “response 1” value shows the length of the part created.
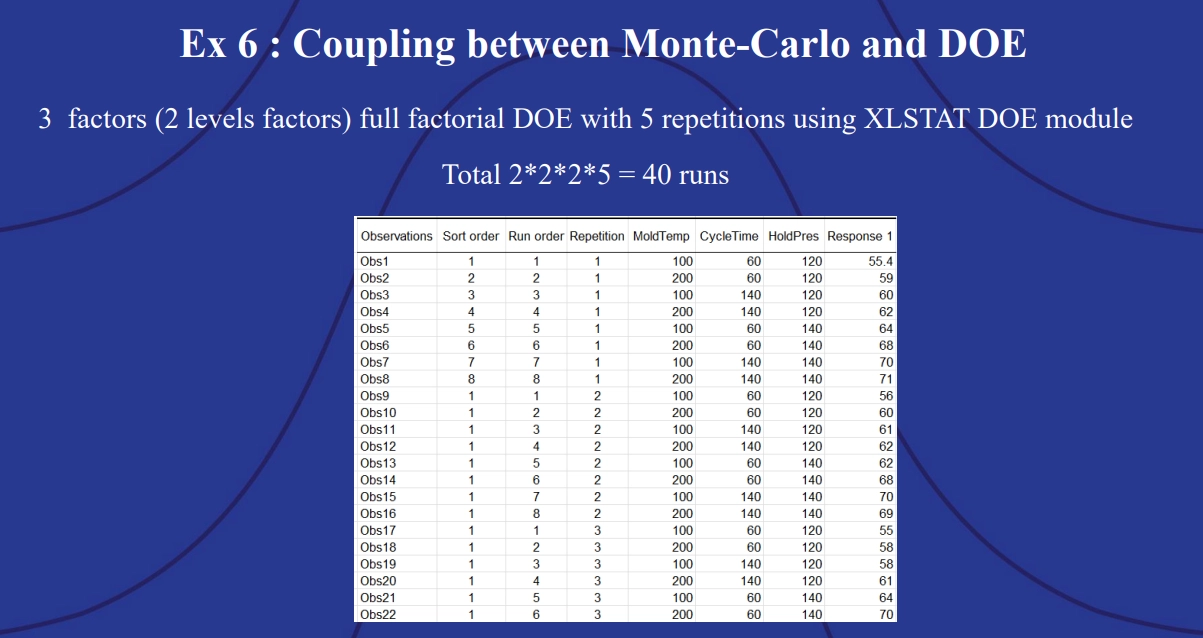
Example 6: Coupling between Monte Carlo and DOE.
XLSTAT then generated a list of solutions – combinations of the three variables that would result in the desired part length. The row circled in red had the lowest cycle time. It also created a formula for finding these best-fit solutions.

Example 6: Coupling between Monte Carlo and DOE.
These were all possible solutions, but were they robust solutions? That is, would a small variation in the input variables result in a tolerably small change in the length of the part created by the injection molding process, or would variations lead to unacceptable parts?
For this second part of the process, Momal went back to @RISK Optimizer. He defined his variables and his constraint (in this case, a part length of 63). He used the transfer function generated by the XLSTAT DOE run.
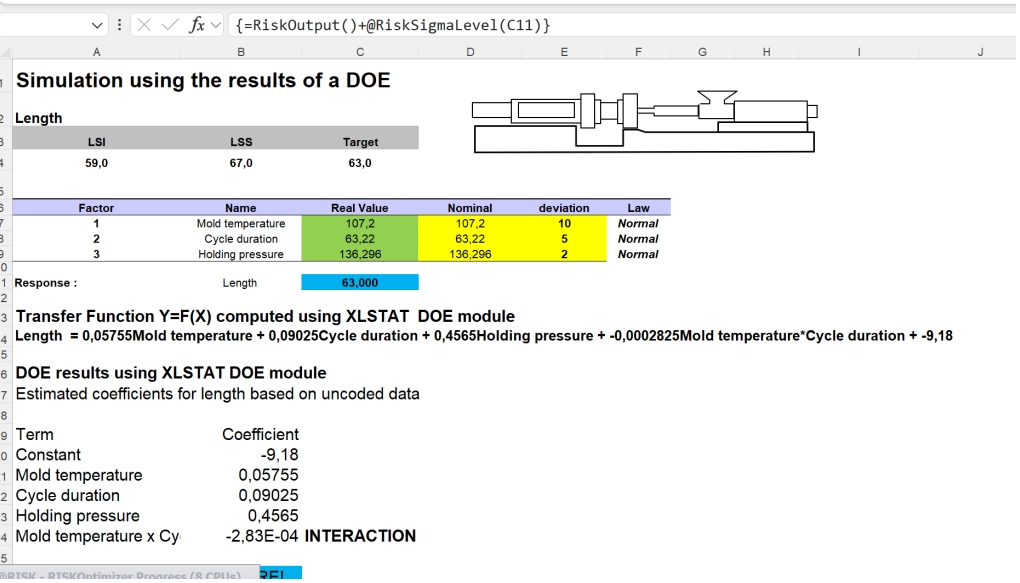
Simulation using the results of a DOE.
Next, he specified that any trials which resulted in a variation of more than three standard deviations (three sigma) in the variables or the length of the part should be rejected.
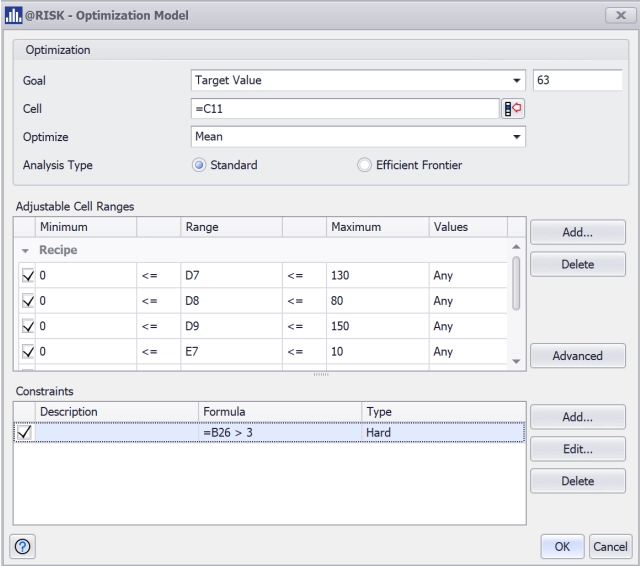
@RISK optimization model set up.
Then he ran the stochastic optimization simulations and watched the outputs in real time.
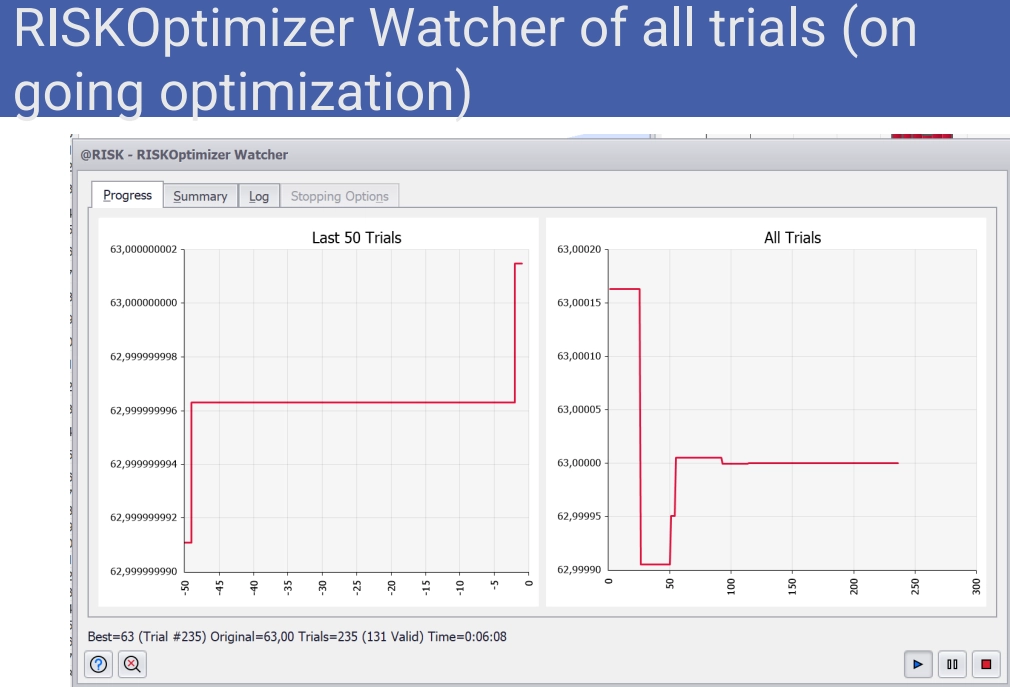
RISKOptimizer Watcher of all Trials (ongoing optimization).
He stopped the trials once a plateau emerged. @RISK Optimizer automatically placed the values from the best trial into his initial workbook.
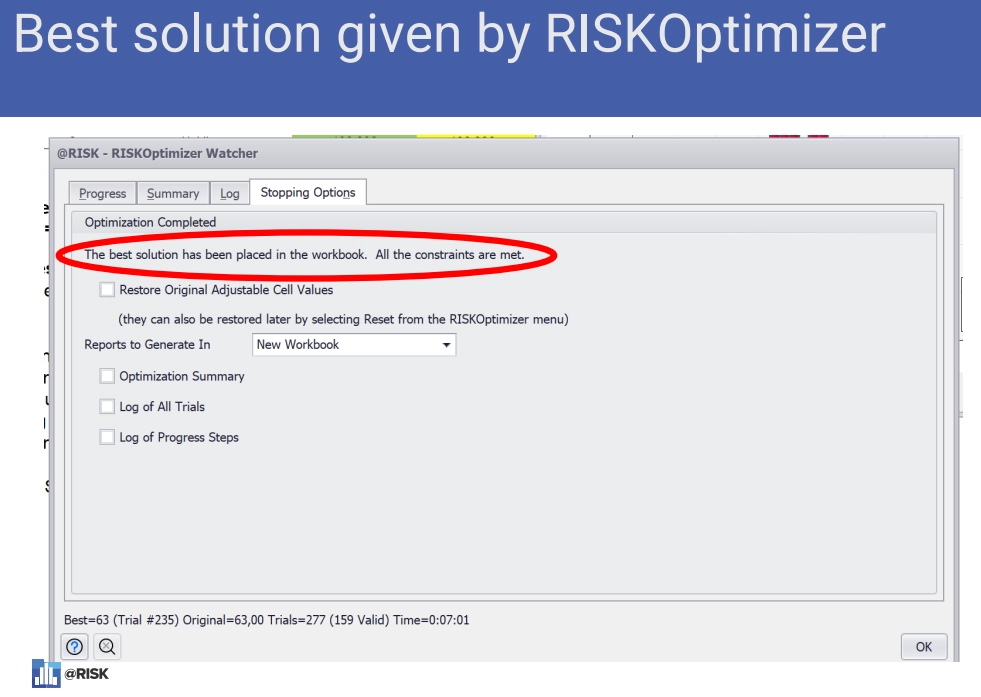
Best solution given by RISKOptimizer.
Sensitivity analysis, this time using a Pareto chart instead of a tornado graph, showed that the primary factor driving variance in trial results was the hold pressure:
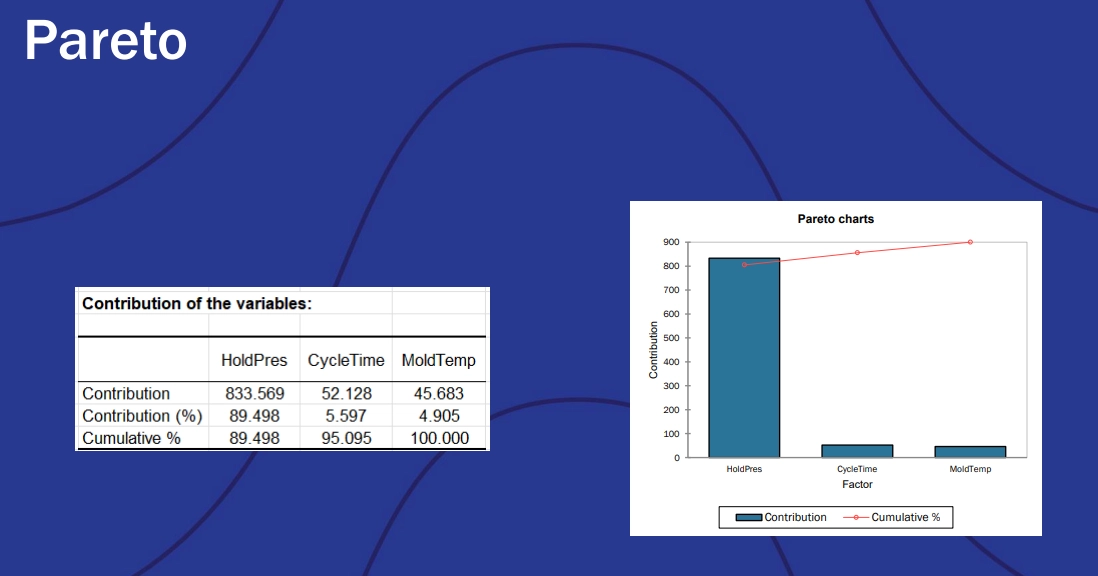
Pareto chart examples including the contribution of the variables.
This gave him experimental data that could be used to inform the manufacturing process without the cost of having to run real-world experiments.
Data-driven manufacturing processes that lead to better efficiency, less waste, and fewer defects – that’s the power of the Lean Six Sigma approach. With @RISK and XLSTAT, you gain a robust suite of tools for helping you make decisions that align with Lean Six Sigma principles.
From better estimates of production line rates to designing experiments to solve manufacturing defect problems, the Monte Carlo simulation and stochastic optimization functions available within @RISK and XLSTAT can support your efforts toward continuous improvement.
Ready to find out what else is possible with @RISK? Request a demo today.
Getting started with Lean Six Sigma might feel challenging, but with ready-made @RISK example models available for download, you can quickly explore the power of Six Sigma – all in Microsoft Excel.
These models can help you test concepts, run simulations, and analyze potential improvements to your methods using @RISK software – offering hands-on experience without starting from scratch.
1. Six Sigma Functions:
A list of @RISK's six sigma functions – what they mean and how they work.
2. Six Sigma DMAIC Failure Rate Risk Model:
Predicts failure rates using RiskTheo functions and defines key quality metrics like LSL, USL, and targets for each component.
3. Six Sigma DOE with Weld:
Demonstrates DOE principles in welding, using @RISK’s functions to optimize process quality.
4. Six Sigma DOE with Catapult:
Illustrates Six Sigma optimization through a catapult-building exercise using Monte Carlo simulation.
5. Six Sigma DMAIC Failure Rate Model:
Calculates defect rates by monitoring product components against predefined tolerance limits.
6. Six Sigma DMAIC Yield Analysis:
Pinpoints production stages with the highest defect rates and calculates process capability metrics for improvement.
Download these models today to quickly explore Six Sigma principles in action with @RISK!
Learn how to apply the six stages of Reflexive Thematic Analysis (Braun and Clarke, 2006, 2020) using NVivo 15 with Lumivero AI Assistant as your data management tool. This webinar will show the practical application of one of the most popular data analysis methods used in qualitative data analysis globally.
See the sample project that comes with all copies of NVivo enacted through each of the six stages as set out in the guidelines from the two seminal authors in this domain. Learn about the many tools in NVivo that may be deployed during coding, retrieval, and reporting on your identified themes and the new NVivo 15 Lumivero AI Assistant.
Since its debut in 2022, OpenAI’s ChatGPT has sparked widespread adoption of generative artificial intelligence (AI) across various industries – from marketing and media to software development and healthcare. This transformative technology is now poised to elevate the field of qualitative data analysis and QDA software.
With the release of NVivo 15, we introduced the cutting-edge Lumivero AI Assistant to our powerful qualitative data analysis software (QDA software). Developed with input from our AI advisory board, the Lumivero AI Assistant offers researchers powerful tools for enhancing their qualitative analysis while maintaining researcher control, data security, and methodological transparency.
In a recent webinar, Dr. Silvana di Gregorio, Lumivero’s Product Research Director and Head of Qualitative Research, walked through how we developed the Lumivero AI Assistant for NVivo 15 and demonstrated how it works in practice for memoing and coding qualitative research data.
Watch the webinar or continue reading to learn more!
Dr. di Gregorio has been working with and on qualitative data analysis software since 1995. At the beginning of the webinar, she took time to remind attendees that qualitative research has always embraced new technology.
“[Qualitative research is] constantly evolving, and that evolution has been always intertwined with technology,” said Dr. di Gregorio.
However, Dr. di Gregorio also noted that qualitative research methodologists have often taken a cautious approach to incorporating new technologies into their practices. “There’s always been kind of a lag between influencers and technology,” she said.
Dr. di Gregorio cited the adoption of the tape recorder as one example of how new technology impacted research practices: prior to the wide availability of inexpensive tape-recording equipment, most data for qualitative analysis was drawn from notes, letters, diaries and other written material. Recording technology enabled the spoken word to be captured and opened a new world of conversational analysis that led to richer insights.
Over the last 30 years, QDA software has played a similar role by enabling researchers to analyze data source materials, including interviews, and develop code structures to describe the data that’s present in those materials. Most QDA software, including previous versions of NVivo, has also integrated early machine learning- or AI-based features such as speech-to-text transcription or sentiment analysis. In all these instances, new technology has been seen as a tool rather than a threat.
“We use tools to manage limitations of our brain power,” Dr. di Gregorio explained. “In relation to qualitative data and analysis, the problems we are trying to solve are how to manage and organize unstructured data or very rich, in-depth data . . . and how to find patterns in that data.”
Even though generative AI seems to have tremendous disruptive potential, Dr. di Gregorio described it as yet another addition to the researcher’s toolbox – not a replacement for qualitative researchers themselves.
However, just like a physical tool in a workshop, AI needs to be used responsibly.
AI tools need to be carefully integrated into research. A January 2024 article in BMC Medical Ethics about the ethical challenges of using AI in healthcare, for example, describes the need to look beyond “the allure of innovation” and ensure that the use of AI benefits all stakeholders.
Qualitative research, like healthcare, has ethical standards that need to be maintained. Incorporating AI in qualitative research carelessly could erode those standards. With this in mind, our team convened an AI Advisory Board to inform and guide the development of NVivo 15 with the Lumivero AI Assistant. Dr. di Gregorio described the diverse makeup of the board as including researchers at every career stage, from PhD candidates to seasoned academics, as well as members drawn from nonprofit and commercial organizations. “Everyone was totally engaged in this process,” explained Dr. di Gregorio.
Insights from the AI Advisory Board led to the development of three pillars guiding our team’s approach to AI. These include:
The AI Advisory Board’s insights also helped refine details of how the Lumivero AI Assistant functioned. For example, when summarizing text, the advisory board came to a consensus that summaries should use the third-person voice instead of the first-person voice. This would prevent the excerpts being mistaken for direct quotes.
The advisory board also decided that researchers should be able to control the automatic coding feature – they could choose whether to let the AI Assistant only suggest codes to the researcher with the researcher doing the actual coding or to allow the AI Assistant to do the coding as well.
Memoing Made Smarter for Better Qualitative Analysis
Dr. di Gregorio transitioned into a practical demonstration, showing how the Lumivero AI Assistant enhances memoing for qualitative researchers.
She began by revisiting the various types of memos used in qualitative research, referencing the work of Paul Mihas, a qualitative research expert (1) at the Odum Institute for Research in Social Science at the University of North Carolina at Chapel Hill. In the description of a memoing course Mihas taught for the ResearchTalk consultancy, Mihas emphasized that "memo-writing strategies help us develop abstract thinking, discern inscribed meaning between pieces of data, and assess collective evidence for emerging claims,” a concept central to the memoing process Dr. di Gregorio explored.
Dr. di Gregorio demonstrated how to revitalize the process of creating what Mihas calls “document reflection” memos using the Lumivero AI Assistant in NVivo 15. A document reflection memo, Dr. di Gregorio explained, “is when you're getting an initial understanding of a transcript or text and try to capture, at a high level, the takeaways – the pivotal moments of what's going on there.”
To illustrate the practical application of this approach, Dr. di Gregorio utilized real-world data from a past research project, offering a hands-on demonstration of how the Lumivero AI Assistant can be employed for document reflection memos.
For her demonstration, she selected data from a University of London mixed methods study conducted more than a decade ago which explored the differences in how 16- to 18-year-olds in Europe perceived community responsibility and political engagement. The study aimed to determine whether these opinions varied based on the post-compulsory secondary education pathways they pursued.
First, Dr. di Gregorio used the Lumivero AI Assistant to generate overall summaries of each transcript which were saved as memos linked to each transcript. Next, she went through the transcripts one at a time, using the Lumivero AI Assistant to summarize individual sections. These were saved as annotations within the project and were clearly labeled as having been AI-generated. Dr. di Gregorio was then able to quickly assign broad codes to each annotated section of the transcript based on the Lumivero AI Assistant’s suggestions.
Having completed a high-level summary of the transcript along with preliminary coding, she was then able to dig deeper into the data. Working through each annotation, she reviewed the section of the transcript from which it was generated. She was then able to add the annotations to the memos, drawing out deeper themes from what the interview subject was saying – what Mihas calls a “key quotation memo” – and adding selected quotes as well as her own thoughts on the developing analysis.
She then reviewed the broad codes she created and used Lumivero’s AI Assistant to suggest child codes (sub-codes) refining the analysis. She created a code memo for each code to review the code across all the transcripts.
The process is summarized in the figure below:

Dr. di Gregorio explained that while qualitative data analysis software of the past has always included memoing tools along with coding tools, the memoing features have typically been difficult to find or researchers jumped to coding immediately. NVivo 15 with Lumivero AI Assistant is designed to help bring memoing back into balance with coding and can be used with all approaches to qualitative methods such as thematic analysis, discourse analysis, narrative analysis and more!
Dr. di Gregorio also noted that NVivo 15’s Lumivero AI Assistant also supports researchers with additional features. These include:
Also, if the researcher feels the summary doesn’t accurately reflect the text they’ve highlighted, they can ask the Lumivero AI Assistant to re-summarize. With NVivo 15, the researcher is always in control.
Better memoing capabilities enable researchers to conduct richer reflexive analysis. The authors of “A Practical Guide to Reflexivity in Qualitative Research,” a 2023 article in the journal Medical Teacher describe reflexivity as the process “through which researchers self-consciously critique, appraise, and evaluate how their subjectivity and context influence the research processes.”
Dr. di Gregorio showed how researchers can use the Lumivero AI Assistant within NVivo 15 to create annotations and memos quickly. Within the memos, researchers can identify not just the themes of the data, but also how the data was gathered.
For example, researchers can create positional memos that notate how the social power dynamics between interviewer and interviewee or the circumstances of an interview might influence the conversation. These reflexive observations can then be included in the final research product – giving crucial context and transparency to audiences who will read and apply the research.
Finally, Dr. di Gregorio noted that researchers need to be transparent about how they use AI tools within qualitative research, being sure to emphasize that AI supports analysis rather than conducting it.
“When you're writing up any methodological section, whether it's a dissertation or whether it's an article for publication, [be] clear about the process of how you did it. NVivo doesn't do the analysis. You are still doing the analysis, but you're using [AI] as an aid,” said Dr. di Gregorio.
Ready to transform your workflow, gain deeper insights into your research question, and streamline your analysis? Don’t wait—request your free demo of NVivo 15 and the Lumivero AI Assistant and discover the next level of qualitative research innovation.
Mihas, Paul Memo Writing Strategies: Analyzing the Parts and the Whole in Vanover, C., Mihas, P, Saldana, J. (2022) Analyzing and Interpreting Qualitative Research: After the Interview, Sage Publications