
As uncertainty becomes a constant in global defense, small and medium enterprises must show they can manage uncertainty and deliver on complex projects to stay competitive. Discover how tools like Predict! and @RISK help transform risk management into a strategic advantage, making it easier to win contracts and meet evolving defense requirements.
Uncertainty has become the norm in the global security industry. As threats evolve and defense priorities shift, demand for advanced risk management capabilities continues to grow. For defense manufacturers—especially small and medium enterprises (SMEs)—this means more opportunities, but also more pressure.
Winning complex defense contracts isn’t just about having the right product. However, SMEs need to prove they can deliver the large, complex projects defense contractors and national agencies need. That means demonstrating a mature approach to risk management.
That’s where tools like Lumivero’s Predict! and @RISK come in. Trusted by major defense organizations and contractors, such as the Australian Defence Force (ADF) and the Five Eyes alliance, they turn risk into a measurable, manageable asset. While no solution can eliminate uncertainty, these tools help transform it into a strategic advantage.
In “Making Data-Driven Decisions with @RISK and Predict! in Defense,” Andrew Lawson, Lumivero’s Senior Account Manager, and Trevor Jay, New Business and Technical Sales Manager demonstrated how @RISK and Predict! work together to help defense contractors of any size save time, reduce costs, and collaborate more effectively.
This article covers the key takeaways from that session, including practical insights for applying risk tools in real-world defense projects.
Defense organizations are moving toward a sovereign model in which they retain as much direct control over their supply chains as possible. This means that suppliers they outsource to must be as transparent as possible about risk.
As discussed in “Risk management in defense: A core pillar of business strategy,” defense contractors and national defense organizations are moving toward continuous monitoring of risk. Siloed risk registers in multiple spreadsheets—no matter how carefully tracked and maintained—are unlikely to meet the risk management maturity standards today’s defense organizations are looking for.
Predict! offers SMEs a centralized risk management system that provides enterprise-wide visibility of risk as well as granular detail for each individual project. Predict! Risk Controller allows for rapid assessment of risks, both in terms of how likely they are to occur and the potential cost impact.
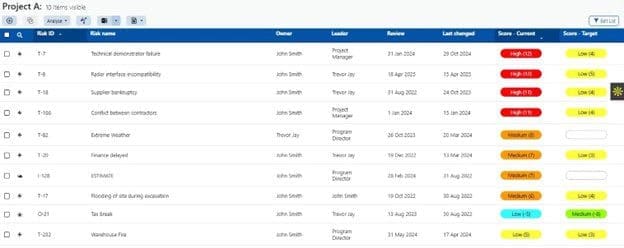
Organizations can define the parameters for each risk or impact level with Predict! Risk Controller.
Defense contractors often have complex procurement guidelines related to risk management. Fortunately, both Predict! and @RISK are already approved by several nations—in fact, in Australia, Predict! is mandated by the ADF’s Capability Acquisition and Sustainment Group (CASG).
Predict! gives SMEs the tools to meet demanding reporting requirements with built-in, customizable reporting features and seamless Excel export options. But it’s not just about compliance—according to Trevor Jay, using @RISK and Predict! can actually help contractors win more business. “It is a competitive advantage to show how you’re managing risk,” he said.
Meeting delivery deadlines is a top priority for defense customers. Timely access to new equipment can directly impact operational readiness, which makes accurate scheduling essential.
@RISK supports this by refining project timelines, highlighting potential delays, and uncovering opportunities to save time.
Take this sample project schedule: the team has set a fixed deadline of January 26.
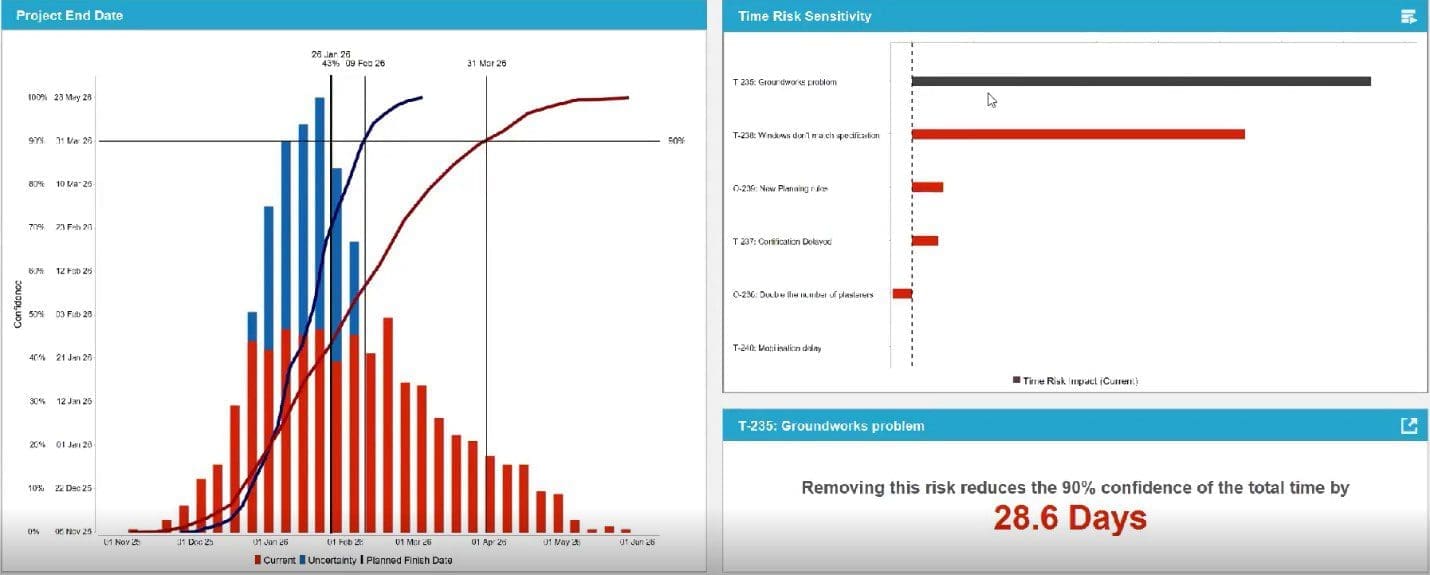
An example of a project end date model. A traditional project schedule with a fixed deadline can’t accommodate uncertainty.
By running a Monte Carlo simulation using the schedule data and the known risks in Predict! Risk Analyzer, it’s possible to evaluate how likely meeting that deadline is. In this case, not very likely: the January 26 date is met in less than 50% of the simulation runs. Using the 90% confidence interval, the actual completion date would be closer to March 31.
Predict! goes beyond creating a probabilistic schedule, however: It also helps identify the risks that have the most impact so you can plan to prevent them. These probabilistic timeline evaluations are especially helpful for “gate” reviews—the reviews conducted between stages of a project, such as moving from R&D to manufacturing.
Bigger projects mean bigger contingency budgets. The traditional method of calculating a contingency budget—a fixed percentage of the overall cost estimate—can result in situations where organizations are expected to hold very large amounts of capital in reserve in case things go wrong. “That’s not necessarily a good thing,” explained Andrew Lawson. “You want to be able to have more of the money to spend on program development rather than just [sitting] there.”
Predict! works together with @RISK to create more precise contingency budgets. Monte Carlo simulation holds the key. By running a probabilistic simulation of a cost-risk analysis, it’s possible to move beyond the fixed contingency budget.
In this example, the overall project budget is £250 million. A 10 per cent contingency budget would come to £2.5 million.
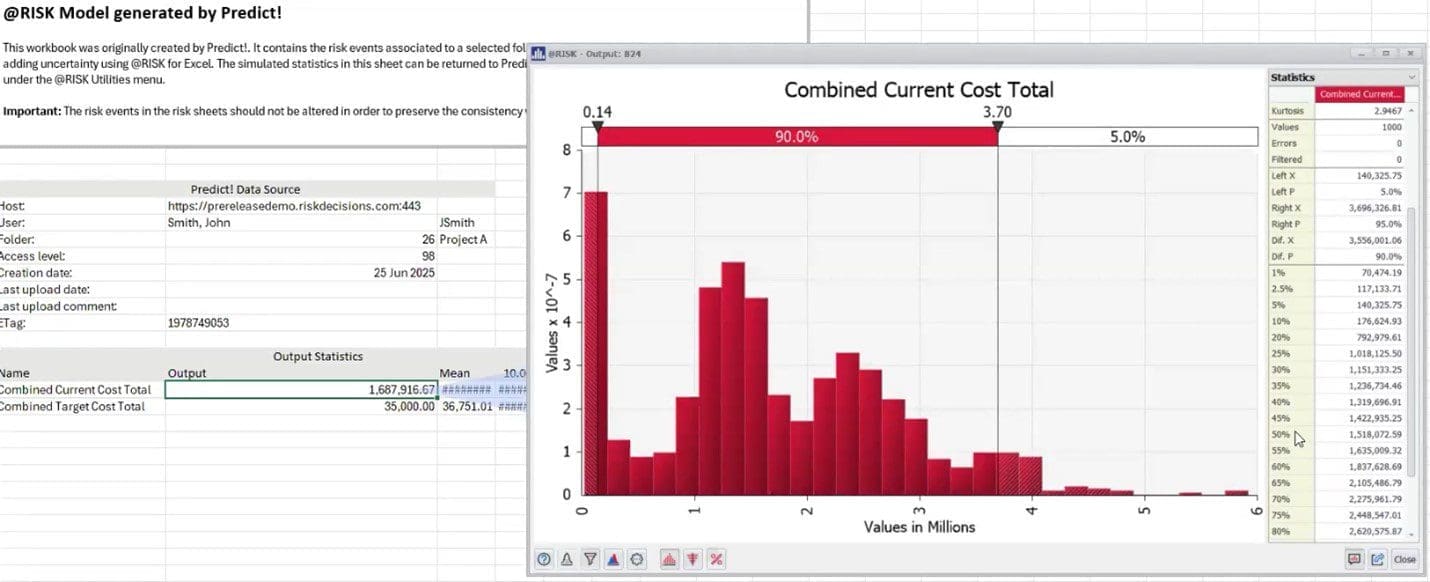
The Monte Carlo simulation, however, indicates that the overspend only comes out to £1.5 million 50% of the time. At the 80 per cent confidence interval, the overspend is £2.6 million. These probabilistic projections allow suppliers to refine their bids—also referred to as “knowledge-based bidding”—and have more targeted discussions about contingency budgets with their customers.
With @RISK, analysts can also drill down to look at which risks have the most impact on budget and begin to discuss options for mitigating those risks. If contingency funds need to be tapped, evidence from Predict! and @RISK can be used to justify the overspend as well—suppliers can revisit their cost-risk analyses with customers or demonstrate that they took steps to prevent or reduce the impact of a negative outcome.
Defense equipment is never built by a single company—it’s the result of collaboration between contractors, prime suppliers, and increasingly, sovereign partners. Predict! and @RISK give defense organizations of any size the tools to communicate and coordinate more effectively.
If multiple collaborators are using Predict!, there are capabilities that allow for shared information across their systems. Working within the same software ecosystem also simplifies communication and reporting: people from different organizations will be able to tap into shared terminology.
From within Predict!, users can generate interactive visualizations that allow for detailed analysis and discussion with all stakeholders. They can examine individual risks or look at correlations between different risks.
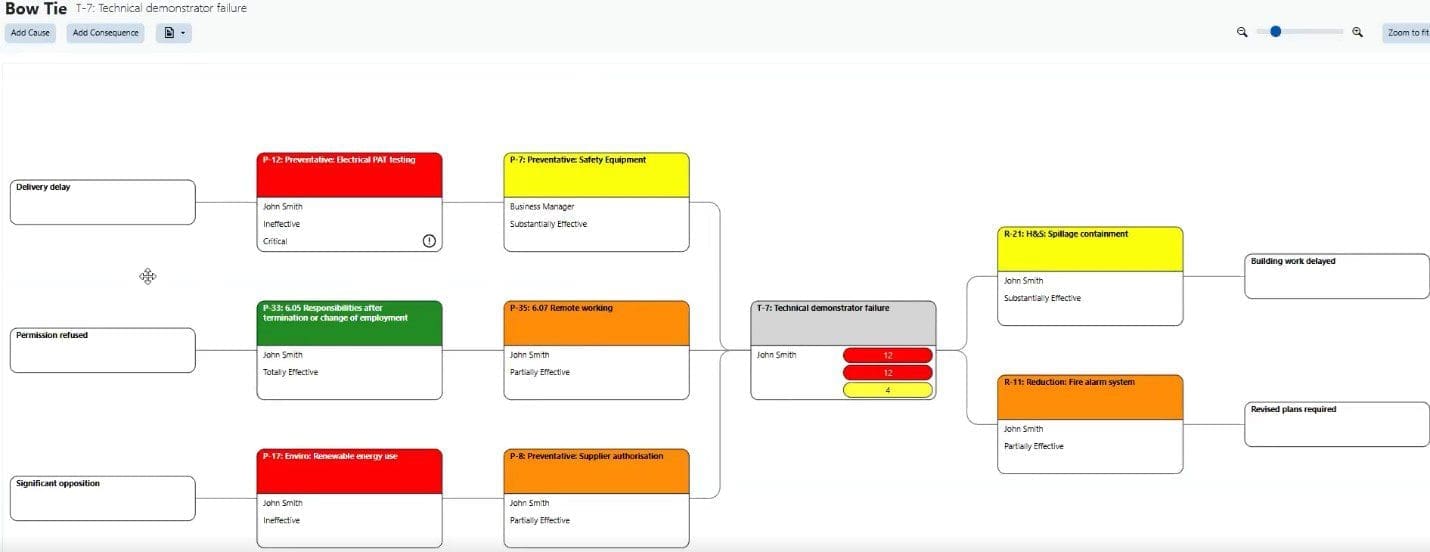
Example of controls in Predict! With a Bow Tie report. This graphic shows how different risks within a project are interconnected, and how addressing one risk affects others.
They can also test scenarios by putting different controls in place to prevent risks, or by rearranging timelines or reallocating budgets to gauge the potential impact on a project. The result is real-time risk management monitoring that accounts for uncertainty and enhances collaboration—ideal for the fast-changing defense industry of today.
Want to learn more about how @RISK and Predict! Suite work together for superior risk management in defense? Request a demo of @RISK or Predict! to see our tools in action.

